RDD란?
spark에서 가장 핵심인 RDD에 대해서 알아보자.
사실 slideshare의 하용호 데이터사이언티스트님의 자료로 부터 많은 걸 얻을 수 있었다. 이 분의 자료는 실로 대단하고 또 쉽다. 나도 넘버웍스 인턴에 지원해보고 싶지만... 아직 부족한듯 하다.
무튼 참고자료
http://www.slideshare.net/yongho/rdd-paper-review?qid=3ff4fd97-e003-46c3-aeb9-dcc3977cdf0d&v=&b=&from_search=1
RDD란?
- 분산되어 있는 변경 불가능한 객체 모음(분산되어 존재하는 데이터 요소들의 모임)
- 스파크의 모든 작업은 새로운 RDD를 만들거나 존재하는 RDD를 변형하거나 결과 계산을 위해 RDD에서 연산(함수나 메소드)을 호출하는 것 중의 하나로 표현
Hadoop MapReduce의 단점?
> Machine Learning에 적합하지 않다.
> 데이터 처리시 HDFS(Hadoop Distributed File System)을 거치기 때문에 IO에서 시간이 오래 걸린다.
Spark는?
> RAM에서 Read-Only로 처리해서 running time이 빠르다.

Data Sharing is slow in MapReduce
- 맵리듀스들 사이에엇 데이터를 재사용하는 방법은 외부 안전한 스토리지 시스템에 데이터르 쓰는 방법뿐이다.
- 반복적이거나 Interactive 애플리케이션은 빠른 데이터 공유가 필요하다. 하지만 디스크 IO 응답시간, 직렬화시간 때문에 맵리듀스는 속도가 느리다. > 하둡 시스템에서 90% 이상의 시간이 HDFS로부터 데이터를 읽고 쓰는데 걸린다.
(하둡의 작동 방법 : 데이터를 찾아서(namednode에 질의) HDFS서 읽은 후 연산하고 그 결과를 로컬에 저장한 후 합쳐서 HDFS에서 다시 업로드 하는 방식)
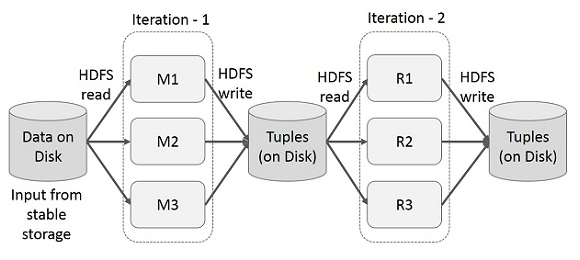

Data Sharing using Spark RDD(Resilient Distributed Datasets)
- it supports in-memory processing computation. 작업 전체의 대상이 되는 메모리의 상태로 저장된다(Sharable)
> 네트워크나 디스크를 사용하는 것보다 10~100배 빠르다. >> 오류시 fault-tolerant 방식이 필요하다.(RAM에만 올려서 사용)


- immutable(read-only), partitioned collections of records
- 스토리지 >RDD변환 or RDD > RDD만 가능
##fault-tolerant 방식이란?
: 컴퓨터 시스템이란 시스템 내의 어느 한 부품 또는 어느 한 모듈에 Fault(장애)가 발생하더라도 시스템 운영에 전혀 지장을 주지 않도록 설계된 컴퓨터 시스템
- DAG (directed acyclic graph 디자인) > 코딩을 하는 것은 실제 계산 작업이 되는 것이 아니라 Lineage 계보를 디자인 해 가는 것 (빈 RDD를 만든다.)
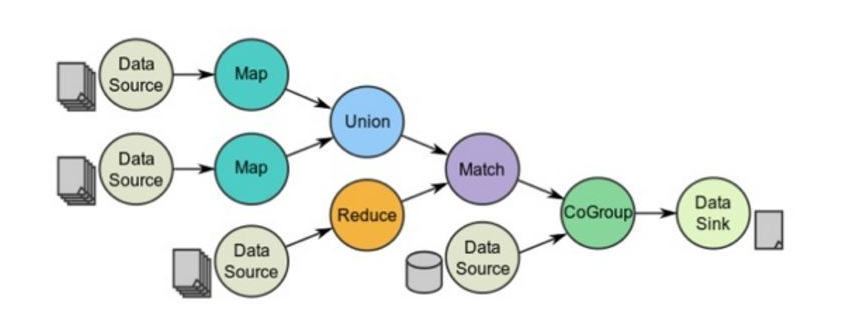
일의 순서대로 빈 RDD를 만들어 가다가 가장 마지막 일이 수행되었을 때, 실제 일을 시작함
> Lazy execution의 개념이 여기서 나옴 - 일을 미루다가 나중에 한 방에 처리
출처 : http://ecycle.tistory.com/12